Weakly Supervised Learning of Rigid 3D Scene Flow





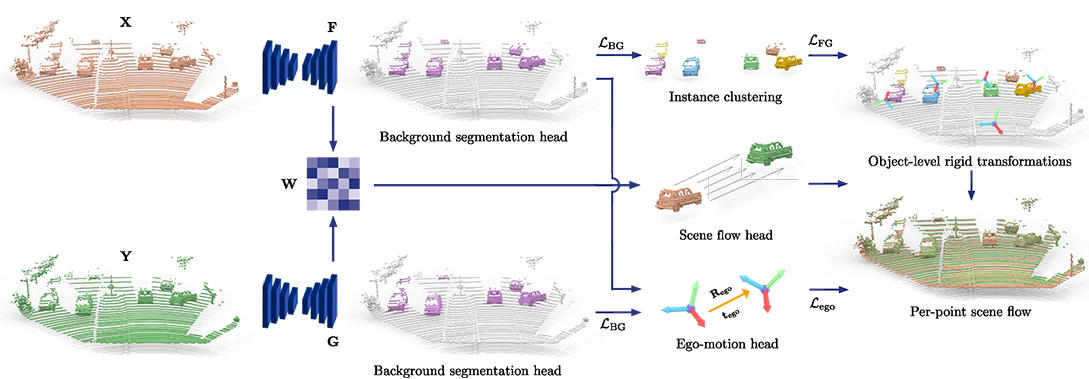
Abstract
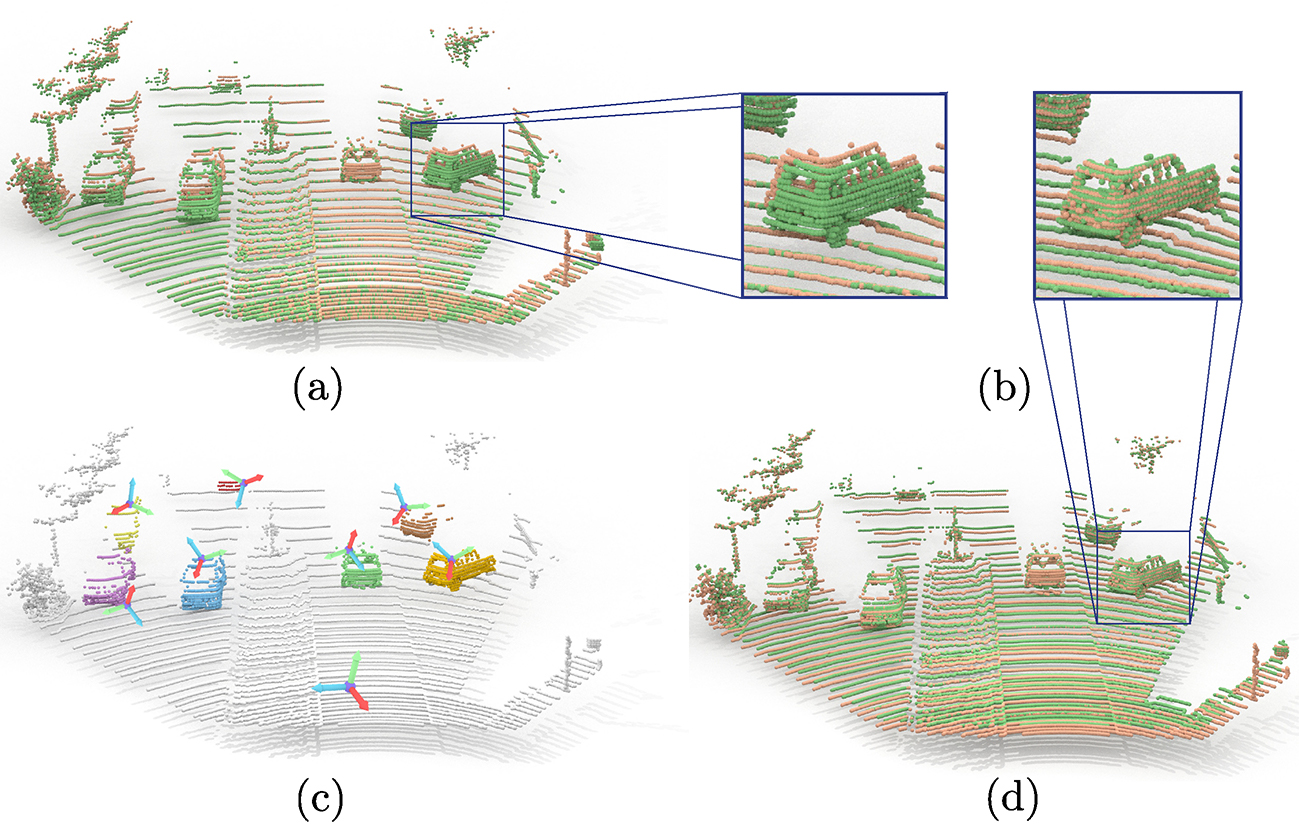
Given two frames as input (a) our method outputs rigid transformation for each agent (c) which can be used to recover pointwise rigid sceneflow. After applying the predicted rigid scene flow, the two frames are aligned (b, d).
Qualitative results

Qualitative results of our weakly supervised method on lidarKITTI (top) and waymo open (bottom). For improved visibility, the EPE3D (top row b,c ) is clipped to the range between 0.0 m (white) at 0.3m (red). As a result of predicting an unconstrained pointwise sceneflow, the rigid objects (car) in the results of FLOT might get deformed (d).